Architecting & Deploying High-Efficiency Data Pipelines for Cryptocurrency Trading & Analysis
Problem
The client, a cryptocurrency investment firm, required an effective system for collecting and managing large volumes of trading data from multiple exchanges. With hundreds of trading pairs to monitor, each exchange presented its own set of data delivery methods and schemas, including various API endpoints for historical data and real-time WebSocket streams. The challenge was to establish a process that could handle this diversity and volume of data efficiently to support the client’s trading strategies and analysis needs.
The project faced a series of interlinked challenges centered around the efficient management of a complex data ecosystem while needing to be scalable to support the growing data demands of the cryptocurrency market, while managing costs to maintain economic feasibility.
Solution
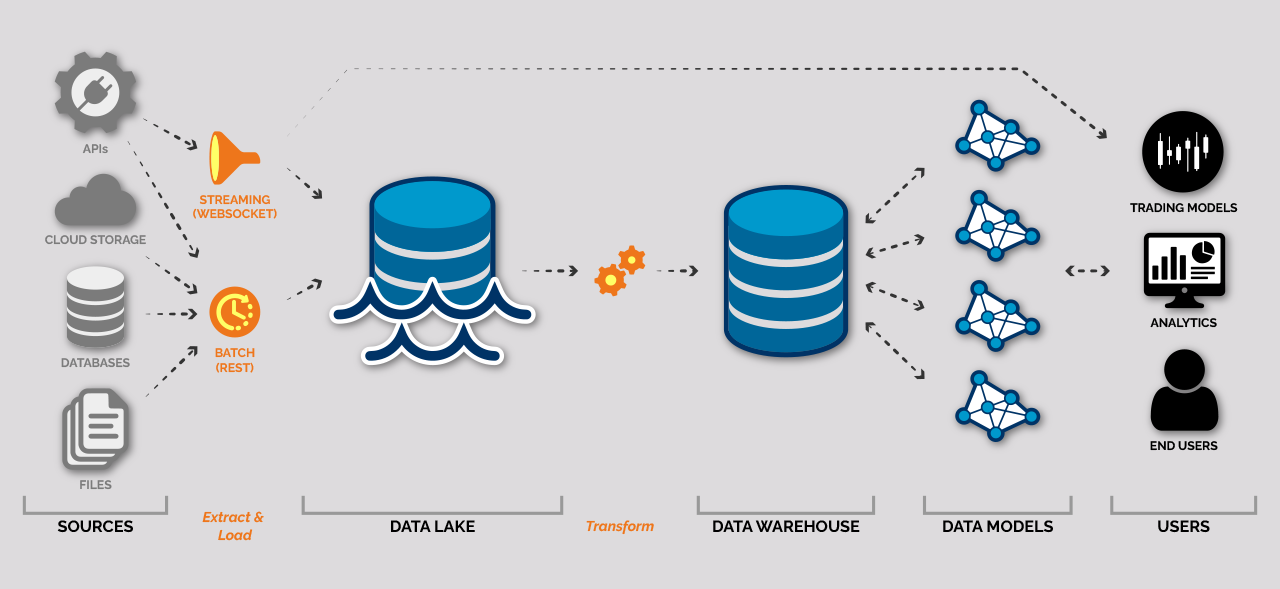
We engineered a cloud-based data pipeline tailored to efficiently manage the collection and processing of trading data. Sourced data, both streaming in real time and at rest, was stored in a data lake prioritizing immediacy and minimal to no processing. Subsequently, the data underwent a series of scheduled transformation processes to validate and standardize it to make it consistent for downstream consumption. The final structured and validated data was reliably stored in an organized and easily accessible data warehouse. Additionally, we crafted versatile data models designed to refine the data into formats that were readily accessible and actionable for both the trading algorithms and market analysts.
Our methodology had to take into account the following specific issues and provide solutions to the challenges raised by each:
- Data Collection Complexity:
To navigate the complexity of collecting data across numerous trading pairs and exchanges, our pipeline employed a highly configurable approach. A set of Python scripts, orchestrated through configuration files, enabled precise control over which data was collected and when. This configuration-driven method allowed for scalability and easy addition of data sources without the need for code changes, streamlining the onboarding of new exchanges and trading pairs.
For the real-time data, particularly from WebSocket connections, we established a redundancy protocol. This involved spinning up multiple instances, ensuring multiple redundant connections to eliminate data loss. The cloud-based infrastructure, built on Google Cloud Platform (GCP), provided the necessary flexibility and scalability. Systemd’s service scheduling capabilities were leveraged to maintain a consistent and reliable data collection routine, operating within the robust security and uptime guarantees of GCP.
- Data Diversity and Velocity:
Our data pipeline was designed to handle the diverse formats and high-velocity demands of trading data. For historical data retrieval via REST APIs as well as real-time data capture through WebSocket APIs, we engineered specialized performance optimized connectors that could process and channel the data without latency or bottleneck issues into our data lake. To accommodate the continuous influx and volume of the real-time market data stream we also have implemented an adaptive buffering system to intelligently manage the throughput of data into the data lake.
- Storage and Accessibility:
For storage and accessibility, we constructed a two-tiered architecture within GCP. The first tier, our data lake, was powered by BigQuery, chosen for its scalability and speed in handling large throughput of data. It served as the initial landing zone for raw data, where minimal processing ensured that data was quickly ingested and available in its original form.
The second tier was a data warehouse, structured to facilitate fast and efficient data access. Here, data was organized into Parquet files, a format selected for its high compression ratios and enhanced read/write performance, especially with analytical workloads. Parquet’s columnar storage format meant that even as datasets grew exponentially, query performance remained optimized.
Accessibility was a key factor; thus, we integrated the data warehouse closely with the trading systems and analytical tools. Analysts could easily access the cleaned and transformed data through a suite of user-friendly tools and interfaces, which were developed to provide immediate insights and support rapid decision-making processes.
- Data Transformation and Organization:
The transformation and organization of data were critical in turning raw information into actionable intelligence. Our pipeline employed scheduled BigQuery queries to deduplicate and normalize the incoming data as a first step. Python scripts further transformed the data according to a Systemd timetable. They handled complex tasks such as data validation, enrichment, and aggregation, ensuring that the data in our warehouse was not only consistent but also optimized. By using Python, we could leverage a vast array of libraries and tools for data processing, which enhanced our capabilities to perform sophisticated data manipulations efficiently.
In the organization phase, we structured the data within the warehouse around time-base, source, and type criteria to streamline data access and improve usability. This organization allowed for quick and cost-effective explorations of large datasets by analysts, providing them with the flexibility to run ad-hoc queries and generate reports with minimal latency.
- Infrastructure Scalability and Cost:
Our infrastructure strategy was tuned to ensure scalability while optimizing costs. In BigQuery, we implemented table partitioning and clustering, which significantly reduced the volume of data scanned during queries, thereby lowering the associated computation costs.
For the data warehouse, choosing to store data in Parquet files proved to be highly cost-efficient. The compact nature of Parquet files, along with their efficient encoding and compression, meant that storage space and, consequently network bandwidth usage were minimized further driving down infrastructure expenses.
The distribution of data ingestion and processing tasks across a fleet of low-cost instances also played a pivotal role in cost management. By leveraging these smaller, more economical instances, we maintained high levels of data throughput and processing power while keeping costs low. This distributed approach allowed us to scale out our resources, matching the infrastructure to the workload without overprovisioning.
- Data Utilization for Decision-Making:
The culmination of our data engineering efforts was to empower the client’s trading strategies and market analysis capabilities. To this end, data models built on top of the data warehouse were tailored to the firm’s specific analytical needs, allowing for a detailed view of the market conditions. These models served as the backbone for a suite of analytical tools, which provided the decision makers with real-time data visualizations and deep-dive analytics.
For the trading systems, the integration was seamless, with the structured data feeding directly into algorithmic trading systems. This allowed the trading algorithms to operate on the most up-to-date information, reacting promptly to market movements and executing trades based on current and historical data trends.
By addressing these considerations, our data pipeline did not just solve for the immediate technical challenges—it also laid the groundwork for a data-driven culture, promoting informed decision-making that is backed by solid data infrastructure.
Technology Stack
The data pipeline was powered by a selection of technologies chosen for their reliability and performance in handling big data. Python scripts automated the collection of trading data via REST APIs and WebSockets, with Google BigQuery serving as the data lake for initial storage. Systemd managed the scheduling of these scripts on a Linux platform. For data transformation, we utilized BigQuery’s scheduled queries alongside Python for complex tasks, with the transformed data being stored in Google Cloud Storage using the Parquet format for optimal access and cost-efficiency. The architecture was completed with custom APIs that facilitated the integration of processed data with the fund’s trading algorithms and analysis tools.
Outcomes & Benefits
The successful deployment of the data pipeline signified a leap forward for the client’s capacity to manage and leverage trading data. By establishing a reliable and continuous flow of information, the new system provided a solid foundation for all data-driven operations. This enhanced reliability proved to be a cornerstone in supporting the firm’s sophisticated trading strategies and comprehensive market analysis.
In terms of operational efficiency, the pipeline’s advanced data structuring and optimization techniques facilitated a notable improvement in data access, fostering a more dynamic and responsive analytical environment. The resultant efficiency gains were not only in time saved but also in the cost-effectiveness of the firm’s data management processes. Overall, the newly implemented data pipeline was a transformative development, underpinning a robust analytical framework that would serve the client’s strategic objectives in the highly volatile cryptocurrency market.